What actually happens internally when we initialize variables in our code? How does our system deal with all of this memory under the hood? I am building my own operating system called vishyOS, and recently I have been working on memory management. In this article, I want to break down what happens under the hood when programs use memory.
What is Memory Management Unit?
Whenever a process runs, it “lives” in RAM. The RAM stores all the variables, pointers, arrays, and other data used by the program. However, RAM itself is just a large collection of bytes. The CPU needs a way to know where each piece of data is stored and how to access it efficiently.
This is where the Memory Management Unit (MMU) comes into play. Think of RAM as a hotel, and the process data as the guests. The MMU acts like the receptionist, deciding which room each guest stays in and keeping track of where everyone is located. When a program tries to access memory, the MMU helps the CPU find the correct location in RAM where that data is stored.
 Source: AI Generated Image
Source: AI Generated ImageDiscover Usable Memory
Not all memory in RAM is actually usable by the operating system. Some regions are already reserved for things such as the bootloader, BIOS/UEFI internals, power management systems, the framebuffer, and other hardware-related components. If the OS accidentally overwrites these regions, the system can become unstable or crash entirely.
Before the OS can manage memory, it first needs to understand what memory exists and which regions are safe to use. This information is provided through a memory map passed by the bootloader during startup. The kernel can then traverse through this memory map and filter out the unusable regions, keeping only the regions marked as available.
Below is an example of traversing through the memory map and printing the type of each memory region in vishyOS:
vishyOS memory map traversal
1fn entry_type_name(entry_type: EntryType) -> &'static str {
2 match entry_type {
3 EntryType::USABLE => "Usable",
4 EntryType::RESERVED => "Reserved",
5 EntryType::ACPI_RECLAIMABLE => "ACPI Reclaimable",
6 EntryType::ACPI_NVS => "ACPI NVS",
7 EntryType::BAD_MEMORY => "Bad Memory",
8 EntryType::BOOTLOADER_RECLAIMABLE => "Bootloader Reclaimable",
9 EntryType::KERNEL_AND_MODULES => "Kernel and Modules",
10 EntryType::FRAMEBUFFER => "Framebuffer",
11 _ => "Unknown",
12 }
13}
14
15pub fn print_memory() {
16 let Some(response) = MEMMAP_REQUEST.get_response() else {
17 framebuffer::print("No memory map\n", 0xFFFFFFFF);
18 return;
19 };
20
21 let mut writer = FbWriter;
22 for entry in response.entries() {
23 let _ = write!(
24 writer,
25 "base={:#x}, len={:#x}, kind={}\n",
26 entry.base,
27 entry.length,
28 entry_type_name(entry.entry_type)
29 );
30 }
31}
32The bootloader (Limine in this case) hands the kernel a memory map through MEMMAP_REQUEST. print_memory grabs that response, then iterates every entry the bootloader reported. For each region it prints the base address, length, and region kind (Usable, Reserved, ACPI, Framebuffer, etc.) to the framebuffer. If the bootloader returns no response, the kernel bails out early with an error message. This is the first step before any allocator can run since the kernel must know which regions are safe to touch.
Knowing that a region is usable is only half the problem. The operating system still needs an efficient way to organize and allocate that memory.
Frames
Let’s go back to the previous hotel analogy. Imagine if, instead of having fixed-size rooms, the hotel created differently sized rooms for every guest depending on their exact needs. Managing the hotel would quickly become extremely complicated because every allocation would be different, and over time the remaining free space would become fragmented and difficult to reuse efficiently.
Memory management has a similar problem. Giving every process an arbitrary chunk of raw memory would be difficult to track and manage efficiently. To simplify this, the operating system divides physical memory into fixed-size blocks called frames. On most modern systems, a frame is typically 4 KB (4096 bytes) in size.
Because memory is divided into fixed-size frames, the OS no longer needs to think in terms of arbitrary byte ranges. Instead of saying, “Give me 20480 bytes,” it can simply say, “Reserve 5 frames.” This makes memory allocation, tracking, and protection significantly easier.
Below is a simple implementation of frames in vishyOS. First, we define the frame size, a small struct to describe each usable region, and the static state the allocator will maintain:
Frame state
1pub const FRAME_SIZE: u64 = 4096;
2
3#[derive(Copy, Clone)]
4pub struct MemRegion {
5 pub base: u64,
6 pub length: u64,
7 pub frames: u64,
8}
9
10const MAX_REGIONS: usize = 64;
11static mut USABLE_REGIONS: [MemRegion; MAX_REGIONS] = [MemRegion {
12 base: 0,
13 length: 0,
14 frames: 0,
15}; MAX_REGIONS];
16static mut USABLE_COUNT: usize = 0;
17static mut TOTAL_FRAMES: u64 = 0;
18
19static mut FREE_LIST_HEAD: u64 = 0;
20FRAME_SIZE is fixed at 4096 bytes. MemRegion records the base, length, and frame count of a single usable region. USABLE_REGIONS is a fixed-capacity array (cap 64) holding every usable region the bootloader reported, and TOTAL_FRAMES tracks the global count. FREE_LIST_HEAD is the head pointer of an intrusive free-list, which we use to allocate frames in O(1) time complexity instead of scanning a bitmap.
Next, we walk the bootloader memory map, keep only usable entries, and carve them into frame-sized chunks:
Carving regions into frames
1for entry in response
2 .entries()
3 .iter()
4 .filter(|e| e.entry_type == EntryType::USABLE)
5{
6 if count >= MAX_REGIONS {
7 break;
8 }
9
10 let aligned_base = (entry.base + FRAME_SIZE - 1) & !(FRAME_SIZE - 1);
11 let end = entry.base + entry.length;
12 let aligned_end = end & !(FRAME_SIZE - 1);
13 if aligned_end <= aligned_base {
14 continue;
15 }
16 let length = aligned_end - aligned_base;
17 let frames = length / FRAME_SIZE;
18
19 unsafe {
20 USABLE_REGIONS[count] = MemRegion {
21 base: aligned_base,
22 length,
23 frames,
24 };
25 }
26 total_frames += frames;
27 count += 1;
28}
29Each usable region's base is rounded up to the next 4 KB boundary and its end rounded down, so every frame sits on an aligned address. If the rounding collapses the region (it was smaller than a frame, or misaligned), we skip it. The aligned length divided by FRAME_SIZE gives the number of frames the region contributes, which we store in USABLE_REGIONS and add to the running total_frames counter.
Once the regions are known, every frame is pushed onto the free list. Allocation and freeing then become a single pointer swap:
Allocating and freeing frames
1pub fn alloc_frame() -> Option<u64> {
2 unsafe {
3 if FREE_LIST_HEAD == 0 {
4 return None;
5 }
6 let addr = FREE_LIST_HEAD;
7 let next = *(phys_to_virt(addr) as *const u64);
8 FREE_LIST_HEAD = next;
9 Some(addr)
10 }
11}
12
13pub fn free_frame(addr: u64) {
14 debug_assert!(addr & (FRAME_SIZE - 1) == 0);
15 unsafe {
16 *(phys_to_virt(addr) as *mut u64) = FREE_LIST_HEAD;
17 FREE_LIST_HEAD = addr;
18 }
19}
20Free frames are not tracked in a separate structure. Instead, the first 8 bytes of each free frame store a pointer to the next free frame, forming a LIFO linked list with no extra memory overhead. alloc_frame pops the head and returns its physical address. free_frame writes the old head into the frame being released and makes that frame the new head. The phys_to_virt call is needed because the kernel runs in the higher half, so it must reach the frame through the HHDM (Higher Half Direct Map) offset rather than the raw physical address.
Virtual Memory
At this point we have a working memory allocator. The kernel can discover usable memory, divide it into frames, and allocate those frames on demand. However, exposing physical memory directly to applications would create several problems. Programs could accidentally overwrite each other's data, memory would become increasingly fragmented over time, and applications would need to know the exact physical locations where their data resides. Modern operating systems solve these issues by introducing an additional layer of abstraction between programs and physical memory: virtual memory.
Virtual memory is a technique in which programs work with virtual addresses rather than accessing physical memory directly. These virtual addresses are translated into physical addresses by the MMU. This abstraction simplifies memory management, isolates processes from one another, and allows the operating system to control how physical memory is used behind the scenes.
Virtual memory also enables processes to use more memory than is physically installed in the system. A program does not need to be fully loaded into RAM at all times. Only the portions that are actively being used need to reside in memory, while less frequently accessed portions can remain in secondary storage such as an SSD or HDD. As different parts of the program are needed, the operating system can move data between storage and RAM, allowing processes to use more memory than the physical RAM available on the machine. This mechanism is known as memory swapping.
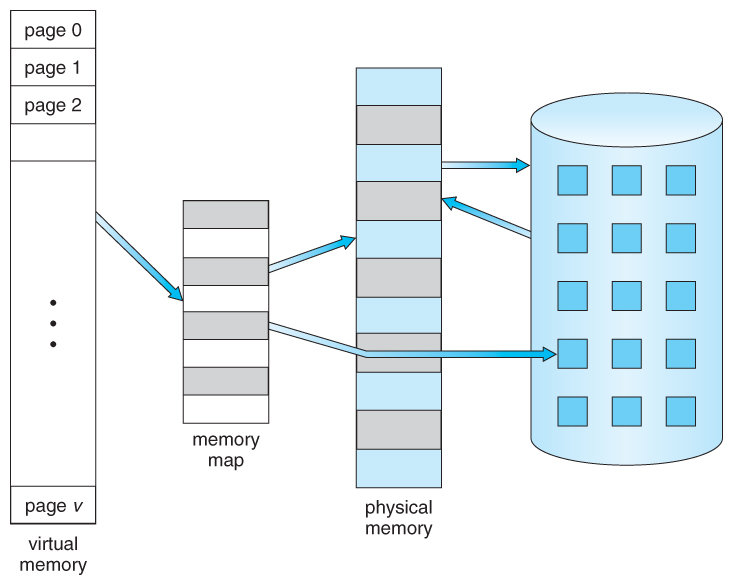 Credits:
Credits: This layer of indirection allows different processes to use the same virtual addresses without interfering with one another. For example, Process A and Process B may both store data at virtual address 0x1000, yet those addresses can map to completely different physical frames. From the perspective of each process, it appears to own its own private memory space even though the underlying physical memory is shared. As a result, processes remain isolated from one another and cannot accidentally overwrite each other's data.
Paging
Similar to physical memory using frames, virtual memory is divided into fixed-sized blocks called pages. On most systems, they are typically 4 KB in size. This fixed-size structure greatly simplifies memory management. Instead of tracking arbitrary ranges of bytes, the operating system only needs to keep track of which virtual pages are mapped to which physical frames.
These pages do not need to be stored in contiguous physical memory. The operating system might map them to completely different physical frames:
- Virtual Page 0 -> Physical Frame 42
- Virtual Page 1 -> Physical Frame 900
- Virtual Page 2 -> Physical Frame 15
From the program's perspective, memory still appears as one continuous address space. Behind the scenes, the MMU uses these mappings to determine where the data is actually located in physical memory.
Now that we have pages and frames, we need a way to keep track of how they are related. This is the job of a page table.
A page table is a data structure maintained by the operating system that stores the mapping between virtual pages and physical frames. Whenever a program accesses a virtual address, the MMU consults the page table to determine which physical frame contains the requested data.
For example, suppose a process has the following page table:
| Virtual Page | Physical Frame |
|---|---|
| 0 | 42 |
| 1 | 900 |
| 2 | 15 |
When the program accesses an address that belongs to Virtual Page 1, the MMU looks up Page 1 in the page table and discovers that it is mapped to Physical Frame 900. The MMU can then calculate the final physical address and access the correct location in RAM. Below I will explain the implementation of Paging in vishyOS.
On x86_64, virtual addresses are 48 bits and the page table is a 4-level tree: PML4 -> PDPT -> PD-> PT. Every level has the same shape, 512 entries of 8 bytes each, which is exactly one 4 KB frame. We start by defining a single entry, the flag bits the CPU recognizes, and the table itself:
Page table entry and table layout
1pub const PAGE_SIZE: u64 = 4096;
2pub const ENTRY_COUNT: usize = 512;
3
4pub mod flags {
5 pub const PRESENT: u64 = 1 << 0;
6 pub const WRITABLE: u64 = 1 << 1;
7 pub const USER: u64 = 1 << 2;
8 pub const HUGE: u64 = 1 << 7;
9 pub const NO_EXECUTE: u64 = 1 << 63;
10}
11
12const ADDR_MASK: u64 = 0x000F_FFFF_FFFF_F000;
13
14#[repr(transparent)]
15#[derive(Copy, Clone)]
16pub struct Entry(pub u64);
17
18impl Entry {
19 pub fn is_present(self) -> bool { self.0 & flags::PRESENT != 0 }
20 pub fn addr(self) -> u64 { self.0 & ADDR_MASK }
21 pub fn flags(self) -> u64 { self.0 & !ADDR_MASK }
22 pub fn set(&mut self, addr: u64, flags: u64) {
23 self.0 = (addr & ADDR_MASK) | flags;
24 }
25}
26
27#[repr(C, align(4096))]
28pub struct PageTable {
29 pub entries: [Entry; ENTRY_COUNT],
30}
31An Entry packs both a physical address and flag bits into a single 64-bit value. The low 12 bits and the highest bit carry the flags such as PRESENT, WRITABLE, and NO_EXECUTE; the middle bits hold the physical address of the next-level table (or of the target frame, at the leaf). ADDR_MASK isolates the address bits. #[repr(C, align(4096))] guarantees a PageTable is itself a single frame, which is required by the CPU.
Each level of the tree is indexed by a different 9-bit slice of the virtual address. The bottom 12 bits are the byte offset inside the final frame:
Splitting a virtual address into level indices
1#[derive(Copy, Clone)]
2pub struct VirtAddr(pub u64);
3
4impl VirtAddr {
5 pub fn pml4_index(self) -> usize { ((self.0 >> 39) & 0x1FF) as usize }
6 pub fn pdpt_index(self) -> usize { ((self.0 >> 30) & 0x1FF) as usize }
7 pub fn pd_index(self) -> usize { ((self.0 >> 21) & 0x1FF) as usize }
8 pub fn pt_index(self) -> usize { ((self.0 >> 12) & 0x1FF) as usize }
9 pub fn page_offset(self) -> u64 { self.0 & 0xFFF }
10}
11Bits 39-47 index the PML4, 30-38 the PDPT, 21-29 the PD, and 12-20 the PT. Nine bits each = 512 entries per table, matching ENTRY_COUNT. The low 12 bits (page_offset) are added to the leaf frame address to produce the final physical address.
Mapping a virtual page to a physical frame means walking these four levels and creating any missing tables along the way:
Mapping a page
1unsafe fn next_table_create(e: &mut Entry) -> Result<*mut PageTable, MapError> {
2 if e.is_present() {
3 Ok(table_ptr(e.addr()))
4 } else {
5 let phys = alloc_table().ok_or(MapError::OutOfFrames)?;
6 e.set(phys, flags::PRESENT | flags::WRITABLE);
7 Ok(table_ptr(phys))
8 }
9}
10
11pub unsafe fn map_page(
12 pml4: *mut PageTable,
13 virt: VirtAddr,
14 phys: u64,
15 leaf_flags: u64,
16) -> Result<(), MapError> {
17 let pml4_e = &mut (*pml4).entries[virt.pml4_index()];
18 let pdpt = next_table_create(pml4_e)?;
19
20 let pdpt_e = &mut (*pdpt).entries[virt.pdpt_index()];
21 let pd = next_table_create(pdpt_e)?;
22
23 let pd_e = &mut (*pd).entries[virt.pd_index()];
24 let pt = next_table_create(pd_e)?;
25
26 let pt_e = &mut (*pt).entries[virt.pt_index()];
27 if pt_e.is_present() {
28 return Err(MapError::AlreadyMapped);
29 }
30 pt_e.set(phys, leaf_flags | flags::PRESENT);
31
32 invlpg(virt.0);
33 Ok(())
34}
35next_table_create returns the next-level table if it exists, otherwise allocates a fresh frame with the frame allocator, zeros it, and installs it in the parent entry as PRESENT | WRITABLE. map_page chains three of these calls to reach the leaf PT, refuses to overwrite an existing mapping, and writes the final entry with the caller's flags. invlpg flushes the TLB for that single virtual address so the CPU does not keep serving a stale translation.
Translation is the same walk in reverse. Given a virtual address, we follow the levels and return the physical address it maps to:
Translating a virtual address
1pub unsafe fn translate(pml4: *mut PageTable, virt: VirtAddr) -> Option<u64> {
2 let pml4_e = (*pml4).entries[virt.pml4_index()];
3 let pdpt = next_table(pml4_e)?;
4 let pdpt_e = (*pdpt).entries[virt.pdpt_index()];
5
6 if pdpt_e.flags() & flags::HUGE != 0 {
7 return Some(pdpt_e.addr() + (virt.0 & 0x3FFF_FFFF));
8 }
9 let pd = next_table(pdpt_e)?;
10 let pd_e = (*pd).entries[virt.pd_index()];
11
12 if pd_e.flags() & flags::HUGE != 0 {
13 return Some(pd_e.addr() + (virt.0 & 0x1F_FFFF));
14 }
15 let pt = next_table(pd_e)?;
16 let pt_e = (*pt).entries[virt.pt_index()];
17 if !pt_e.is_present() {
18 return None;
19 }
20 Some(pt_e.addr() + virt.page_offset())
21}
22At each level, if an entry is missing we return None. The extra HUGE checks handle 1 GiB pages (at the PDPT) and 2 MiB pages (at the PD), where the walk stops early and the leftover low bits of the virtual address become the offset inside the huge frame. Otherwise we descend all the way to the PT and add page_offset to the leaf frame address. This is the same operation the MMU performs in hardware on every memory access.
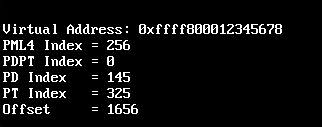 Source: vishyOS Screenshot
Source: vishyOS ScreenshotWe can look at an example of virtual address 0xffff800012345678. It is split into four 9-bit indices and a 12-bit page offset. The MMU first looks at entry 256 in the PML4, then entry 0 in the PDPT, followed by entry 145 in the PD, and entry 325 in the PT. The final page-table entry contains the physical frame backing this virtual page. The offset (1656 bytes) is then added to the frame's base address to produce the final physical address.
Conclusion
Starting from a raw memory map provided by the bootloader, we discovered usable memory, divided it into frames, built a frame allocator, created page tables, and mapped virtual pages to physical frames. Together, these components create the illusion that every process owns its own continuous address space while allowing the operating system to efficiently share and manage physical memory.
While vishyOS currently implements only the foundations of memory management, these foundations are what enable more advanced features such as page faults, demand paging, process isolation, and memory swapping. Those will be the next steps as the memory subsystem continues to evolve.
